Hablemos con honestidad. Estás viviendo la «resaca» del hype de la IA.
Hace tres meses, tu equipo presentó un piloto de Agente de IA que dejó a todo el directorio con la boca abierta. Respondía preguntas, resumía documentos, ¡casi que servía café! Era brillante. Era el futuro. Se aprobó el presupuesto. Hubo aplausos.
Hoy, tres meses después, ese mismo agente, ya en un entorno de producción beta, es un desastre. Se cae. Alucina respuestas que no tienen sentido. Tarda una eternidad en contestar. Y la confianza que tanto costó ganar… se está evaporando más rápido que trago de cortesía en fiesta de fin de año.
Tu primer instinto, y el de todos, es señalar al culpable más obvio: el Modelo de Lenguaje Grande (LLM). «¡El GPT-4 se volvió tonto!» «¡El modelo de Claude no entiende nuestro negocio!» «¡Necesitamos un LLM más nuevo, más grande, más brillante!»
Déjame ahorrarte el próximo ciclo de presupuesto. Detén la caza de brujas contra el LLM. Estás culpando al cerebro por un fallo del sistema nervioso. Estás gritándole a J.A.R.V.I.S. porque el traje de Iron Man tiene un corto en el guante.
El problema casi nunca es el LLM. El problema es una arquitectura de software débil que ignora la orquestación y el manejo de excepciones.
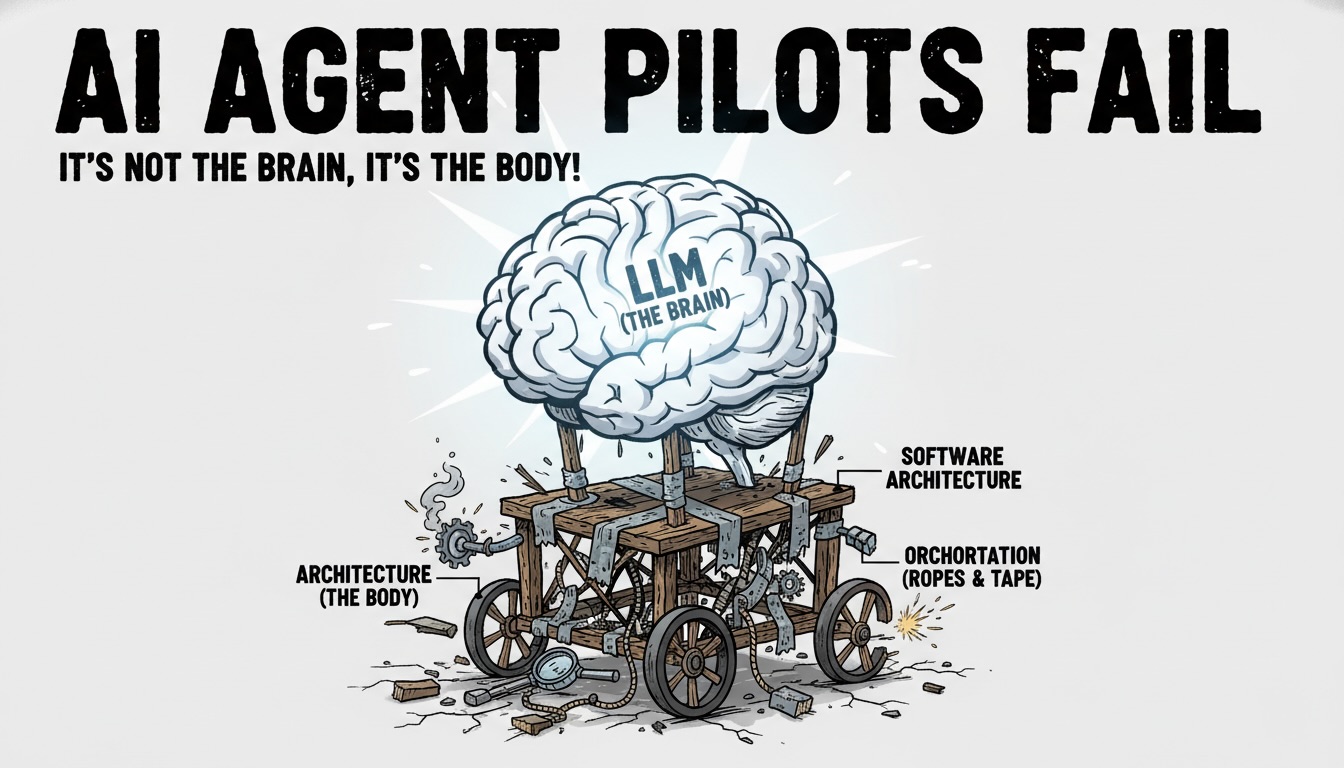
El Diagnóstico: Tienes un Cerebro de Fórmula 1 en un Chasis de Juguete
Piénsalo de esta manera. Un LLM, sea GPT, Claude, Llama o el que quieras, es un motor de cognición puro. Es un cerebro en un frasco. Es un genio caótico. Es un chef con tres estrellas Michelin.
En tu demo de piloto (el sandbox), le diste a ese chef una cocina impecable, todos los ingredientes perfectamente medidos, los cuchillos afilados y cero presión. Obvio que cocinó un plato espectacular.
Producción no es eso. Producción es el mundo real. Es una cocina caótica en pleno sábado por la noche. Los pedidos llegan mal escritos (inputs de usuario), el proveedor de vegetales se retrasa (API externa caída), se corta el gas (error 500) y el lavaplatos renunció (fuga de memoria).
Si tu chef estrella no puede cocinar en ese caos, ¿es culpa del chef?
No. Es culpa del que diseñó la cocina. Es culpa del Maitre D’ que no sabe gestionar las comandas. Es culpa de la orquestación.
¿Qué Diablos es la «Orquestación» (Y por qué es el 90% del Juego)?
Si el LLM es el rockstar (talentoso, temperamental, un poco impredecible), la Orquestación es el roadie, el manager y el ingeniero de sonido, todo en uno. Es el sistema que rodea al LLM y que de hecho hace el trabajo.
Un Agente de IA «real» no es solo un prompt. Es un flujo de sistema:
- Paso 1 (Intención):
- Paso 2 (Recolección): El Agente necesita datos. ¿De dónde? ¿Una API interna? ¿Una base de datos SQL? ¿Un PDF? El orquestador debe saber a quién llamar.
- Paso 3 (La Llamada): El orquestador llama a esa API.
- Paso 4 (El Desastre): La API tarda 8 segundos en responder. O peor, devuelve un error 404.
- Paso 5 (Cognición): El orquestador (con suerte) maneja el error, busca un plan B, obtiene los datos, y recién ahora se los pasa al LLM (el cerebro) junto con un prompt claro.
- Paso 6 (Respuesta): El LLM responde, y el orquestador debe formatear esa respuesta para el usuario.
El prompt y la magia del LLM ocurrieron solo en el Paso 5. Todo lo demás, todo ese andamiaje que define el éxito o el fracaso… eso es arquitectura.
Los 3 Errores de Arquitectura que Están Matando tu Piloto
Tu piloto falla porque tu arquitectura de sandbox probablemente asumió que el mundo era perfecto. El mundo real no lo es. Estos son los errores que estás pagando caro:
1. El Abismo del Manejo de Excepciones
Este es el asesino número uno. Tu prompt puede ser una obra de arte, pero ¿qué hace tu agente cuando la API de Salesforce.com está en mantenimiento? ¿Qué pasa si el JSON que recibe está malformado? ¿O si el documento que debe leer simplemente no existe?
En un sandbox, nunca probaste esto. En producción, pasa todo el tiempo.
Un agente sin un manejo de excepciones robusto es como un auto sin frenos. Cuando el LLM no recibe lo que espera, ¿qué hace? Se rinde, da un error genérico o, peor, alucina una respuesta para «rellenar el silencio». Y ahí es cuando pierdes la confianza del usuario.
2. El Monstruo de la Latencia y las Llamadas en Cascada
En el demo, todo era instantáneo. En producción, tu agente necesita consultar 3 sistemas distintos para armar una respuesta. 2 segundos de la API A + 3 segundos de la API B + 1.5 segundos de la API C + 2 segundos del LLM… y tu usuario ya esperó 8.5 segundos por una respuesta.
En el mundo de la gratificación instantánea, 8 segundos es una eternidad. El usuario refrescará la página, pensará que se rompió y abandonará la tarea.
Una buena arquitectura piensa en paralelizar llamadas, en usar caché, en diseñar flujos que minimicen la espera. Una arquitectura de piloto simplemente… espera.
3. El Espejismo del «Grounding» (RAG)
Para que el agente no invente cosas, usamos RAG (Generación Aumentada por Recuperación). En simple: le «adjuntamos» los documentos correctos al LLM para que base su respuesta en ellos. Suena genial.
Pero el RAG no es magia. Es un problema de arquitectura de datos. ¿Cómo encuentras el documento correcto entre 100,000 archivos? ¿Cómo divides ese documento? ¿Cómo te aseguras de que la información recuperada (el «contexto») es 100% relevante?
Si tu sistema de búsqueda (el retriever) es mediocre, le estás pasando al LLM los ingredientes equivocados. Volvemos al chef: le pides un pastel de chocolate y tu arquitectura le pasa sal y pescado. El chef hará lo que pueda, y el resultado será una aberración. ¿Culpa del chef?
La Cura: Deja de ser un «Prompt Engineer» y sé un Arquitecto de Sistemas
El hype nos hizo creer que el trabajo era «escribir prompts». Esa es la punta del iceberg. Es la cereza del pastel. El verdadero trabajo, el que hace que un proyecto de IA pase de ser un juguete de demo a una herramienta de producción, es la ingeniería de software.
Frameworks como LangChain, LlamaIndex o el mismo Asistente de OpenAI no son «constructores de IA». Son frameworks de orquestación. Son herramientas para construir el sistema nervioso, no el cerebro.
Así que, ¿cómo salvar el proyecto?
- Audita tus Puntos de Fallo:
- fallbacks
- Monitorea Como un Halcón: No puedes arreglar lo que no ves. Implementa logging y monitoreo obsesivo. ¿Cuánto tardó cada paso? ¿Dónde falló? La data te dirá exactamente dónde se rompe tu arquitectura.
- Optimiza tu RAG como un Producto: La búsqueda y recuperación de datos no es un feature, es el cimiento. Trátalo con esa seriedad.
- Adopta una mentalidad de «Sistema»: El LLM es solo un componente. Una pieza más en el diagrama de arquitectura. Es la pieza más glamorosa, sí, pero depende de todas las demás.
La buena noticia es que el problema tiene solución. Y no requiere un LLM nuevo y más caro. Requiere volver a los fundamentos: buena y robusta ingeniería de software.
Deja de culpar a J.A.R.V.I.S. Es hora de dejar de hacer carritos de juguete y empezar a construir el traje de Iron Man.


